Big data is what happened when the cost of storing information became less than the cost of throwing it away. — George Dyson
My university had impressively old libraries filled with impressively older books. I’d wander through the stacks and try to spot the volume with the dustiest spine. If a book looked particularly unloved, I’d allow myself to open to its back flap and inspect the last stamped date of circulation. If it was old enough, I’d quickly thumb through the pages, cleaning interior dust as I went. Once in a long while, I’d find the time to read a page or two before I put the book back on its shelf — back into its information purgatory.
The Sciences Library was already fifteen stories tall, but I always imagined they could lift off its brutalist top and add unbounded new floors to house the growing collection. The architects had their work cut out for them, of course, as they’d probably need to grow the skyscraper exponentially fast. Over time, as I wandered the new floors above the clouds, I’d see fewer students — until one day I’d see none at all. After all, we could build the books but we couldn’t build ourselves fast enough to keep dusting off their pages, to say nothing of reading them. This realization was lovely if bittersweet: so many dusty books; so many pages so long forgotten. Without the hope of rediscovery, information purgatory looked indistinguishable from far crueler entropy.
{kind=link}
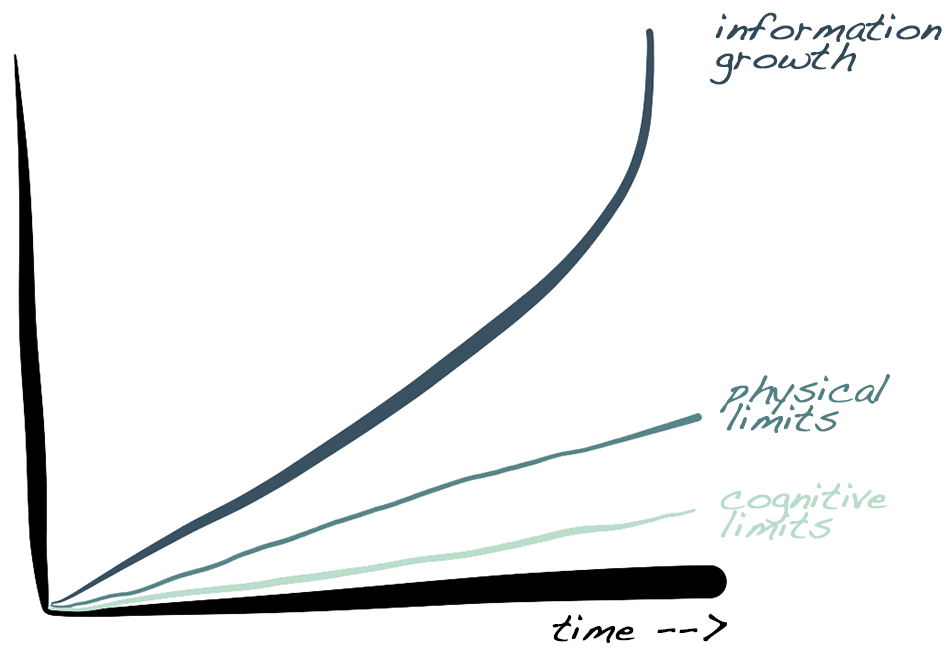
Today, it’s bits, not pages. We can happily grow our library without bound. This time, there’s no need to break the endowment, and our structural engineers have the problem well in hand. Yet the same curves I imagined for the real apply just as well to the virtual: top-line information growth, an exponential over time; middle-line physical limits on our consumption, a linear function of our population; bottom-line limits on our ability to cogitate what we consume, a linear function of population at its hopeful best. Is the story again bittersweet: so many bits, soon to be so long forgotten?
{kind=link}
We can never again visit all the bits by hand, but we now have tools that vastly amplify our reach. Today, search engines are seen as a powerful convenience; a means to find a thing we want. If the trends continue, perhaps they become something far greater: perhaps they become a light on our shared humanity. A century hence, what is a cultural anthropologist to do? Why, spin up a custom algorithm that explores a floor of the library long since unvisited, racing brilliantly amongst the stacks and dusting off a few forgotten bits along the way. Our understanding of ourselves will be inexorably linked to automated exploration of the bits we’ve left behind. We have the tools, but the algorithmic bestiary has only begun: a dizzying array of mechanical critters exploring our heritage. This, then, is George Dyson’s “big data”: a strange new land where information purgatory is hopeful and alive for perhaps the very first time.